15 Jun, 2022
'/%3E%3Cdefs%3E%3ClinearGradient id='a' x1='0' y1='-5' x2='11' y2='-5' gradientUnits='userSpaceOnUse'%3E%3Cstop stop-color='%2300F'/%3E%3Cstop offset='.339' stop-color='%23A0A'/%3E%3Cstop offset='.677' stop-color='red'/%3E%3Cstop offset='1' stop-color='%23FA0'/%3E%3C/linearGradient%3E%3C/defs%3E%3C/svg%3E)
6 min read
The Data Handbook
How to use data to improve your customer journey and get better business outcomes in digital sales. Interviews, use cases, and deep-dives.
Get the book
Questions related to activating customer data can quickly become overwhelming. Enterprise customer data stacks have accumulated layers over the years, leaving teams often not even knowing what lives in it. This article aims to bring clarity to your thinking by understanding what are the emerging technologies such as Customer Data Platforms (CDP) and what these technologies can enable.
What is a Customer Data Platform?
The CDP Institute defines CDP as a packaged software offering a persistent and unified customer database which is accessible to other systems (CDP Institute). This kind of definition can be helpful for quickly distinguishing which tools are CDPs and which are not. But the reality is that businesses do not care if they have a “real CDP” or not, they care about the use cases that their customer data stack as a whole enables.
The term CDP is used in a varied way by vendors to signal that the tools they are offering have either above-average data ingestion, processing or channel orchestration capabilities. While there are no clear market leaders in the CDP space, there is still a lack of clear definition for what it actually is and many vendors try to own the term. Especially if you ask CDP vendors, CDP can basically be any kind of digital tool that stores, moves or utilises customer data.
The need for a CDP is clear in the digital-first era: organisations want to enable real-time personalisation and targeted messaging in multiple channels, as well as, build marketing-driven databases where a variety of customer data can be fed to purpose-tailored machine learning models for deriving insights.
Do most organisations benefit in pursuit of emerging use cases such as real-time personalisation? It depends on the current level of maturity of utilising customer data in general. Most organisations will still achieve significantly better ROI by focusing efforts on optimising their utilisation and processes around already established technologies, mainly: CRMs and Marketing Automation tools.
Let’s say you are embarking on this journey to real-time personalisation and advanced customer analytics. To make these use cases possible, a few problems need to be addressed. Firstly, customer data is typically siloed and needs to be consolidated from different digital touchpoints and backend systems. Different customer identifiers need to be unified under a single profile, and the data needs to be made available for a variety of data-consuming technologies.
The three building blocks of customer data stacks
Looking at a variety of CDPs, they ultimately seem to aim at one thing, and that thing is to make your customer data stack whole. There are however major differences and types of “CDP” tools to consider, each stitching and completing the stack in its own unique ways. One will be better off if they can position the tools at least within these building blocks.
On a high level, the capabilities to build great data-enabled customer experiences can be summed up simply into three main categories. These three categories roughly comprise what is called a customer data stack.
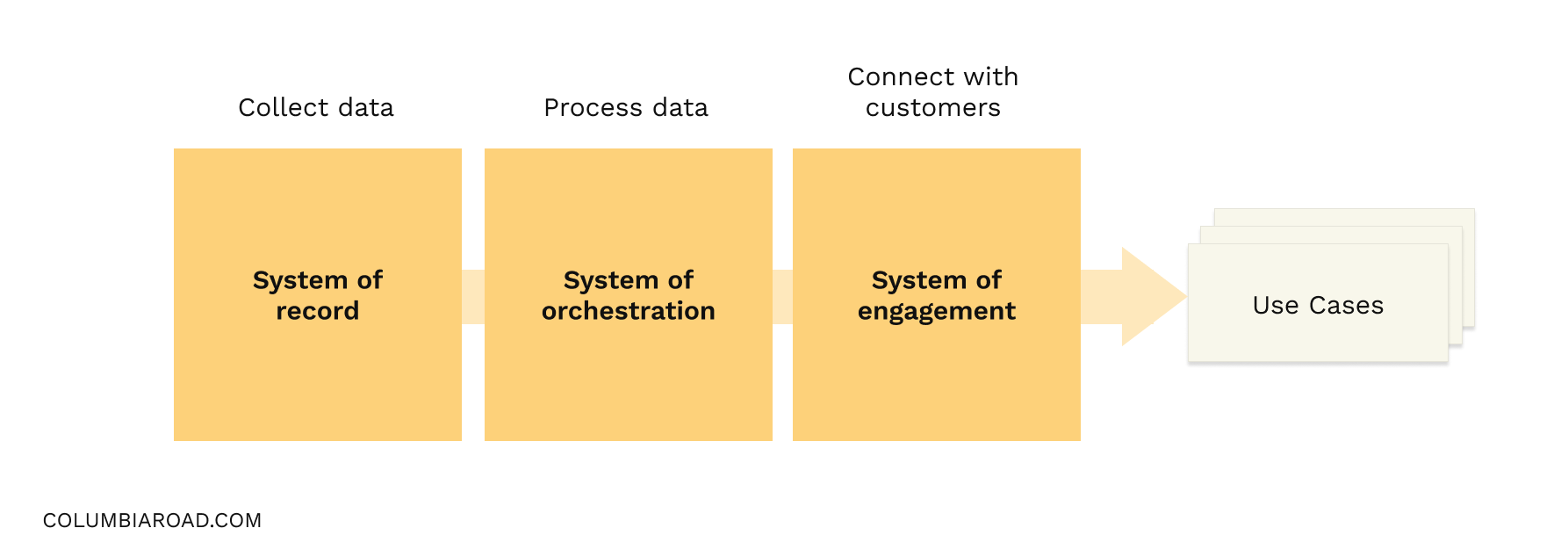
- Listening - Systems of record
- Thinking - Systems of orchestration
- Speaking - Systems of engagement
Typically, technologies focus on one or two of the capabilities listed above. Marketers would want to operate in the sweet spot of all these, operating a stack which seamlessly integrates these elements. Historically, this has meant a lot of work coming from business toward IT and data teams – implementing copious amounts of point-to-point integrations.
A “real CDP” typically sits in-between the Thinking and Speaking layers, making data available by new data flows and possibly enabling marketers to perform advanced orchestration of customer journeys. But the stack as a whole is rarely about a single technology or even a suite of technologies that would be implemented in an enterprise context. A lack of understanding of what capabilities are actually implemented by any given “CDP technology” and what should be taken care of by some other technology in the stack, is a clear route to a disastrous implementation.
Examples of packaged CDPs with different capabilities
The one key differentiator for a customer data platform is the idea of resolving identities under a single customer profile. In the digital world, this means consolidating different customer identifiers, which are subject to change across devices and browsers. Therefore, it is more common than not, that CDPs of this sort include some ready-made SDKs to also collect data from multiple digital touchpoints, web and mobile among others. Another benefit of the packaged CDPs is the sheer amount of pre-made connectors to most common SaaS tools (CRMs, Marketing Automation tools) and most databases (AWS, Snowflake, etc.)
To start with a concrete example of how CDPs differ, let’s take a look at platform strategy driven approach and Salesforce Customer Data Platform. Salesforce's CDP is focused on leveraging your existing suite of Salesforce Clouds, while also extending the data collection capabilities to SDKs and your own databases via the out-of-the-box connectors. It also provides advanced capabilities for non-developers to build rules to unify customer profiles. This kind of CDP can provide a fast time-to-value if you already have the other Salesforce Clouds such as Sales, Service and Marketing Clouds in place. Setting up and operating this kind of suite of tools is definitely a case for organisations that might have utilised Marketing Cloud already to a full extent.
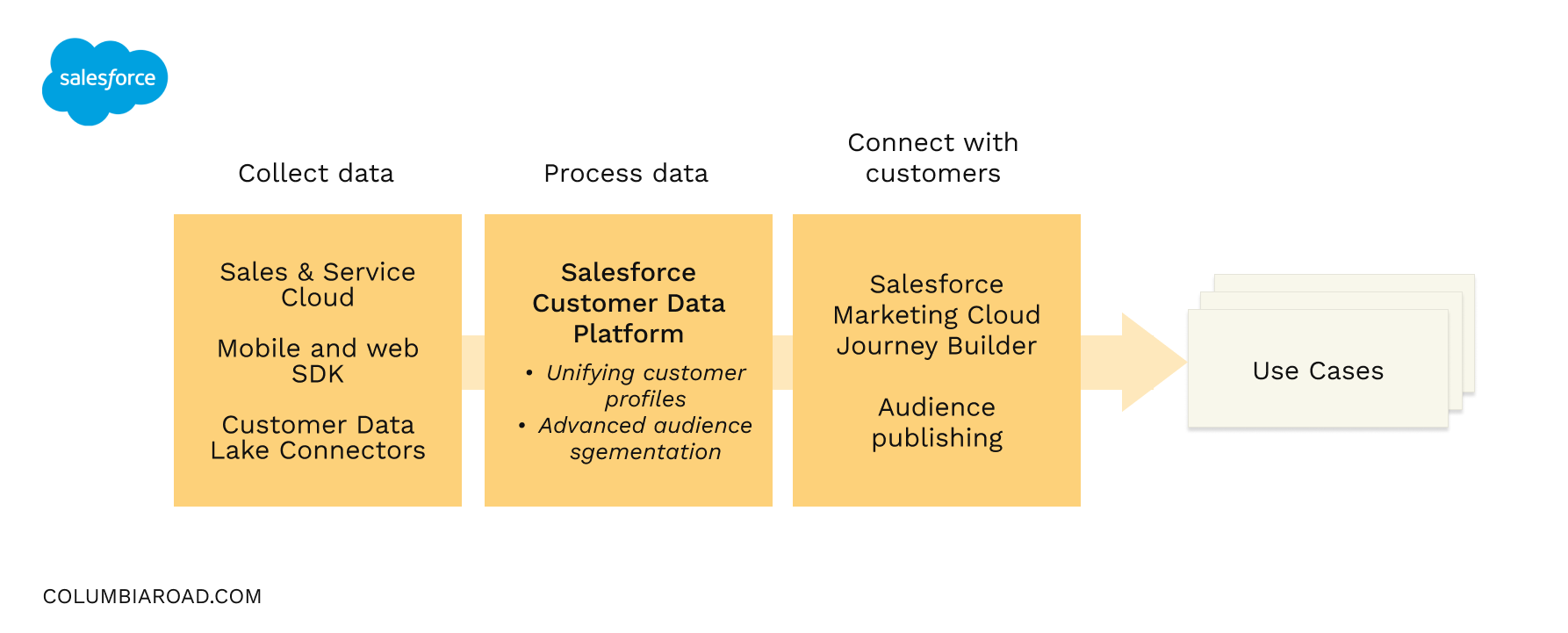
Example of a Salesforce customer data stack where Customer Data Platform plays the role of building better capabilities for marketers to utilise variety of data.
There are also other enterprise systems that have capabilities in all of the “boxes”, such as Emarsys and Exponea. They have SDKs to collect behavioural data, advanced analytics, ability to house persistent and relationally complex customer data and utilise that data to target and trigger messaging in multiple channels. These “new kids on the block” are many, and while most might lack the credibility of Segment or Salesforce, depending on the target market, they have significant benefits to user experience by concentrating advanced capabilities under easy-to-understand UI for a technical marketer.
While typical marketer-lead CDPs might lean toward channel focus, there are also platforms which place the most focus on the middle layer: processing data for efficient orchestration across multiple channels. One of these solutions is Optimove, which has many points of parity with other CDPs: providing a high amount of integration and advanced segmentation capabilities out of the box while having focus on marketer’s usability and easily utilisable machine learning models.
Then again, some CDPs focus more on data collection. Twilio Segment can enable behavioural data collection from multiple touchpoints, web tracking, mobile SDK, and product analytics, among others. However, it is not a typical CDP as the tool does not have persistent storage of data. It is merely used as a collection tool and a hub for real-time integrations - streaming customer profiles, behavioural data and transactions efficiently through built-in connectors toward your digital tools and custom databases.
For the rising need to support faster time to value for these stakeholders who usually utilise some SaaS tools in their customer-facing digital activities, there has been a steep rise in iPaas, and lately even more, with reverse-ETL technologies. Platforms such as Hightouch focus purely on providing tools that can sync data from your Customer Data Lake toward any tool or platform, with easy-to-use configuration instead of code. In this case, the CDP is actually a constellation of the organisation’s existing customer data lake and the data pipelines done on Hightouch.
Enterprise customer data stack is a constellation of built and bought solutions
Custom Data lakes hosted on cloud seem like the robust approach for enterprises. Rather than building dependency on SaaS systems, which might have relatively shorter life cycles. Having a steady base and centralised hub to build on and to integrate possible new systems of record is a lot of work, but still less than implementing and maintaining tens or hundreds of point-to-point integrations and managing data flows between them.
When building the architecture for scale, it is paramount to aim for an architecture where data is productised. Instead of generating multiple use cases or target system-specific datasets out of the raw data, the data model should be planned and built around clear entities in the data lake. Distinct entities such as customers, transactions and web behaviour can then be exposed from the data lake via a microservices approach. Each data product is then consumed by a specific archetype and delivered to use case-specific systems for the data to be activated.
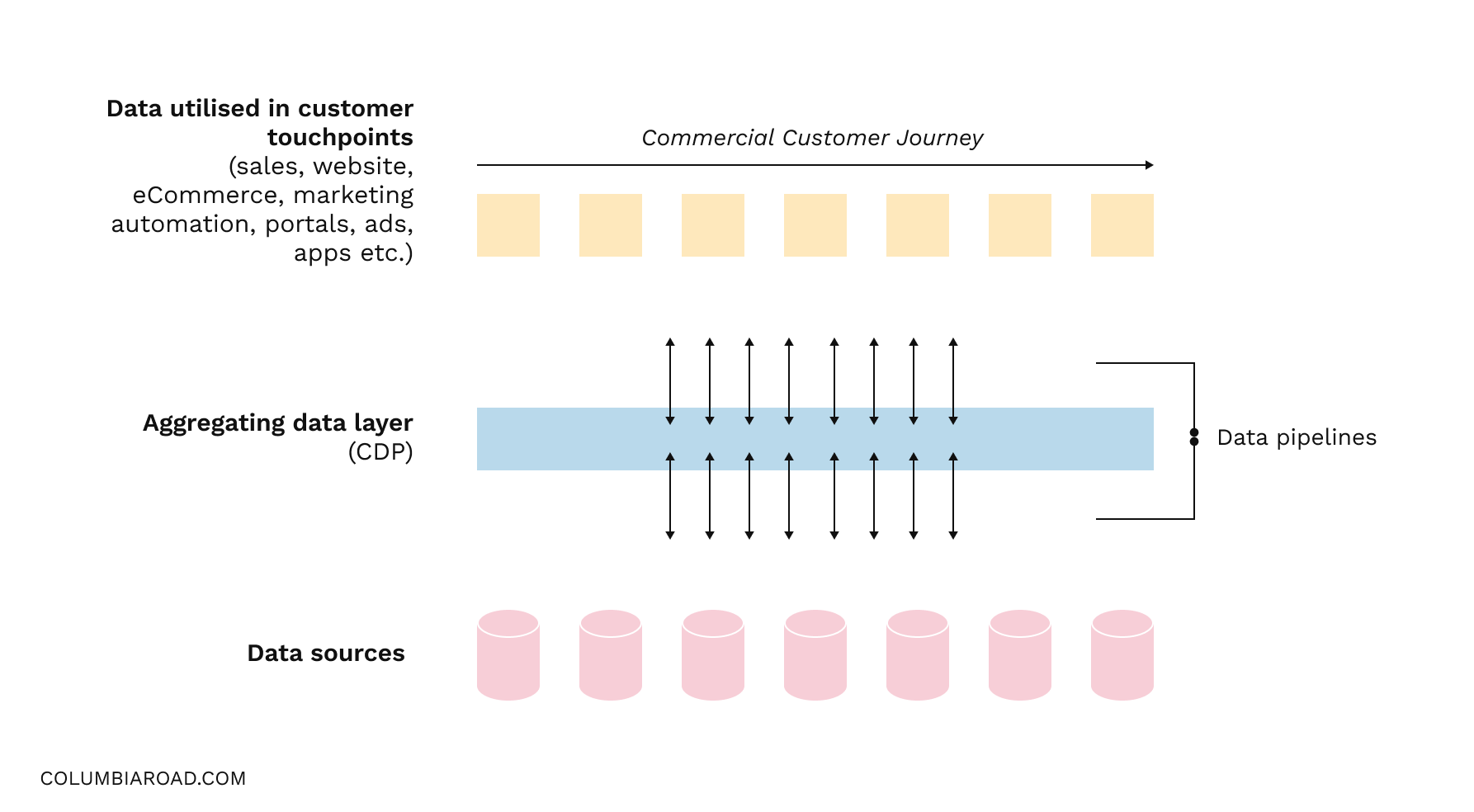
Still, for many, the implementation effort of a data lake is realising close to zero customer-facing within the first years. More often than not, the initiatives are owned by separate data teams within IT, who focus on building the vast horizontal capabilities in the stack. Ultimately, the value is realised in vertical use cases where customer-facing use cases or insights are acted upon. To speed the time-to-value, it might make sense to consider implementations a use case vertical at a time, which does not sacrifice the scalability of the platform.
How to go about building your next-level customer data stack
We at Columbia Road, Futurice Family, along with our sister company Recordly realise that building a holistic customer data stack is not a one-size-fits-all. We recommend combining two critical approaches:
- Top-down – what you want to achieve and what kind of use cases you aim for
- Bottom-up – what data you have and what you can start collecting.
In technical terms, it means clarifying the data “verticals” of most promising business cases, but also securing the source systems and data models that need to be in place. When it comes to technology choices, it can certainly make sense to approach packaged tools from the perspective of faster time to value, especially when there are synergies to your pre-existing architecture.
Having a perspective for a few years ahead is needed, as you should also keep in mind that different stacks need different skills to operate effectively. As your stack evolves fast, the organisational competence to utilise it needs to stay on par.
Did you find this topic interesting? Maybe our Data Handbook is something for you! The aim of the book is to help a sales, marketing, IT or ecommerce leader to formulate an overall understanding of the critical themes for turning data into concrete business impact. The book includes interviews with global thought leaders on the topic as well as industry experts from companies including Supermetrics, Singular Society and Kesko.
